SC25 showed continued strength of the HPC community with about 16,500 attendees, 560 exhibitors, and the usual fastest network, SCinet, this time with a pack bandwith of 13.7 TBytes/s. And as usual, the latest edition of the TOP500 list was released on Monday. Not a lot of changes in the TOP10 this time, but several noteworthy developments, including the first officially rated exaflop system in Europe at the Julich Supercomputer Center.
Join Shahin and Doug as they analyze and discuss the new TOP500 list. They go over HPL, HPL-MxP, HPCG, Green500, geographical distribution, vendor distribution, and other observations.
The new TOP500 list of the most powerful supercomputers was released today at the ISC conference, with a new addition to the top 10. Tune in as Shahin and Doug go through the list with their commentary and analysis as they go over the details, key takeawats, how continents, companies, and architectures fair, and cover the full suite of benchmarks: HPL, Green500, HPCG, HPL-MxP (AI), IO500, and MLPerf.
SC24 is off to a great start with over 17,000 attendees, 480 exhibitors from 29 countries, and new TOP500 list that features a new champion! “The new El Capitan system at the Lawrence Livermore National Laboratory in California, U.S.A., has debuted as the most powerful system on the list with an HPL score of 1.742 EFlop/s. It has 11,039,616 combined CPU and GPU cores and is based on AMD 4th generation EPYC processors with 24 cores at 1.8GHz and AMD Instinct MI300A accelerators. El Capitan relies on a Cray Slingshot 11 network for data transfer and achieves an energy efficiency of 58.89 Gigaflops/watt. This power efficiency rating helped El Capitan achieve No. 18 on the GREEN500 list as well.”
Join Shahin and Doug as they analyze and discuss the new list. As usual, they go over notable additions, performance efficiency, power efficiency in the Green500 list, the difficult HPCG benchmark that usually sets the lower bound of system performance.
Last year about this time, we had the opportunity to discuss the state of HPC and the Aurora supercomputer with Rick Stevens and Mike Papka of Argonne National Lab. In the run up to SC24, we are delighted to do the same! Rick and Mike kindly carved out some time to join us for another wide ranging discussion.
We discuss Aurora, Exascale, AI, reliability at scale, technology adoption agility, datacenter power and cooling, cloud computing, quantum computing.
We’d like to encourage you to also listen to episodes 15 and 16 where we discuss AI in science with Prof. Stevens, and epsideo 75 referenced above, just before SC23.
Rick Stevens is Argonne’s Associate Laboratory Director for the Computing, Environment and Life Sciences (CELS) Directorate and an Argonne Distinguished Fellow. He is also a Professor of Computer Science at the University of Chicago. He was previously leader of Exascale Computing Initiative at Argonne.
Michael Papka is a senior scientist at Argonne National Laboratory where he is also deputy associate laboratory director for Computing, Environment and Life Sciences (CELS) and division director of the Argonne Leadership Computing Facility (ALCF).
We are delighted to have Dr. Mike Heroux as special guest to discuss HPC software in general and the Exascale Computing Project (ECP) software efforts in particular. Topics include performance vs. portability and maintainability, heterogeneous hardware, the impact of AI on workloads and tools, the emergence of Research Software Engineer as a needed role and a career path, the convergence of commercial and HPC software stacks, and what’s on the horizon.
Dr. Heroux is a senior scientist at Sandia National Laboratories and scientist-in-residence at St. John’s University in Minnesota. He’s been with both of those organizations for more than 25 years. Mike was also the ECP’s Director of Software Technologies. While that project has been completed, Mike’s software work has continued to receive funding. Earlier in his career, Mike was with SGI, and Cray. His focus is on all aspects of scalable scientific and engineering software for parallel computing architectures.
We are delighted to be joined by Christine Chalk, physical scientist at U.S. Department of Energy and federal program manager for the Exascale Computing Project (ECP) and the Oak Ridge Leadership Computing Facility. Christine is also responsible for budget formulation for Advanced Scientific Computing Research (ASCR) and management of the Advanced Scientific Computing Advisory Committee and the Computational Science Graduate Fellowship. Topics include the ECP project and what made it so successful, how policy turns into a budget, and the growing importance of the role of women in HPC.
What does a supercomputer center do when it’s operating two systems on the TOP-10 most powerful computers? Well, it starts planning for what’s next. The center is Oak Ridge National Lab (ORNL), and that’s exactly what it is doing. We caught up with Matt Sieger, Project Director for the 6th iteration of the Oak Ridge Leadership Computing Facility (OLCF-6) to get a glimpse of the project, its objectives, status, and timelines.
Meet Discovery, the supercomputer that is being planned to succeed Frontier (the current #1 at 1.19 exaflops in 64 bits) while Summit (the current #7 at 148.8 64-bit petaflops) continues to work alongside it.
With a Ph.D. in Physics from the University of Illinois at Urbana-Champaign and stints at the Pacific Northwest National Laboratory (PNNL), Intel’s fabrication facilities in Portland, Oregon, and a Knoxville-based startup as Chief Software Architect, Matt joined ORNL in 2009. He moved to OLCF as Deputy Project Director for the Frontier project in 2018, and was selected to lead the effort to procure the successor to Frontier in 2021.
As SC23 approaches, we were fortunate to catch up with Rick Stevens and Mike Papka of Argonne National Lab for a wide ranging discussion. In addition to an update on the Aurora supercomputer and TOP500, we also discuss the need and challenged of building a national exascale capability, developing teams and bench strength, the risks and opportunities of AI for science and society, the trend towards integrated research infrastructure (IRI), and what’s next for the exascale initiative. We’d like to encourage you to also listen to episodes 15 and 16 of this podcast where we discuss AI in science with prof. Stevens.
Rick Stevens is Argonne’s Associate Laboratory Director for the Computing, Environment and Life Sciences (CELS) Directorate and an Argonne Distinguished Fellow. He is also a Professor of Computer Science at the University of Chicago. He was previously leader of Exascale Computing Initiative at Argonne.
Michael Papka is a senior scientist at Argonne National Laboratory where he is also deputy associate laboratory director for Computing, Environment and Life Sciences (CELS) and division director of the Argonne Leadership Computing Facility (ALCF).
In this episode of Industry View, we are delighted to have a rare opportunity to catch up with none other than Pete Ungaro, long time luminary and admired leader in HPC/AI. Mr. Ungaro is a globally recognized technology executive, among the “40 under 40” by Corporate Leader Magazine in 2008, and CEO of the year by Seattle Business Monthly for the year 2006. He was most recently SVP/GM of High Performance Computing (HPC), Mission Critical Systems (MCS), and HPE Labs at HPE. Previously, he was president and CEO of Cray Inc. until its acquisition by HPE. Prior to joining Cray in 2003, Mr. Ungaro served as Vice President of Worldwide Deep Computing Sales for IBM.
In this episode of Industry View, we cover the Cray journey as it became the clear winner in exascale systems, the HPE acquisition, the challenges of delivering a new extreme-scale system during COVID, a look at HPC software, storage, power and cooling, and quantum computing, the opportunities and challenges of AI, and the geopolitics of high tech.
From the early days of supercomputing through the stellar success of the Exascale Project, few HPC luminaries have played such an integral and leadership role in supercomputing as Dr. Paul Messina. So as we look at the annual observance of the Exascale Day on October eighteenth, we were delighted to get a chance to discuss the journey to Exascale with someone who has led and overseen 10 orders of magnitude in performance improvement. Dr. Messina’s distinguished career dates back to the early 70s. After earning his PhD at the University Of Cincinnati, Paul joined Argonne National Lab in 1973. He was involved in building programming language for the original Cray 1. At CalTech, he was the director of the Center for Advanced Computing Research. In 1998 to 2000 he led the DOE-NNSA Accelerated Strategic Computing Initiative (ASCI) program which was at the heart of DOE’s Science Based Stockpile Stewardship strategy and a significant catalyst for supercomputing innovation. Dr. Messina was also the first director of the Exascale Computing Project (ECP) starting from 2015 until late 2017.
University of Delaware Professor Sunita Chandrasekaran joins us to discuss exascale software, directive based parallel programming, the emergence of research software engineering as a career, what AI will mean for the industry, and the importance of communication and community among teams.
Doug is in Hamburg, Germany for the ISC23 conference where the 61st edition of the TOP500 list has just been published. 30+ years of systematic data on the highest performing computer architecture and configurations is a treasure trove and we look at the top line insights from this installment, including the GREEN500,HPCG, and the AI-inspired mixed precision benchmark HPL-MxP.
This episode starts to look at HPC software and its convergence with traditional enterprise IT software. We cover the evolution of software through phases of IT, the roster of relevant HPC software from development environment to system administration, and end-user requirements, and traditional and emerging applications. Future episodes and guests will focus on various aspects of HPC software.
Post-Exascale Computing for the NNSA (National Nuclear Security Administration) is the subject of a new report by a distinguished working and review committes comprised of notable supercomputing experts. The report examines the trajectory of high-end supercomputing to date, future needs, emerging technologies, advances in scientific disciplines and computational methods, and the workforce, industry partnerships, and roadmap necessary for successful deployment. We bring you a summary of the report’s key findings and recommendations. @HPCpodcast is delighted that two of the panelists were guests of this show in recent months.
When soldiers are software engineers a new warfare emerges. Modern warfare is similar to, and needs, high tech product development with fast cycles and incremental improvement. The new Technopolitics section starts with the role of software engineers enlisted in the Ukrain war. Next is the House Committee on Science Space and Technology hearing on “US, China, and the Fight for Global Leadership: Building a U.S. National Science and Technology Strategy”. New and substantial funding (£800m) for the UK Exascale program promises to bring the UK into the exascale world by 2046. (This was subsequently complemented by another £2.5B for quantum technologies.) Under the HPC-AI section of the podcast, we discuss the recent changes to the Intel high-end GPU roadmap and lament the lost opportunity to communicate that better.
We are delighted to have Kathy Yelick as our special guest to celebrate the Exascale Day (10/18). Dr. Yelick is the Robert S. Pepper Distinguished Professor of Electrical Engineering and Computer Sciences and the Vice Chancellor for Research at UC Berkeley, and Senior Faculty Scientist at Lawrence Berkeley National Laboratory. Her expansive perspective and expertise led us through a wide ranging discussion including the impact of exascale computing on society, the role of HPC in helping set public and international policy, multi-physics research, advancing software technologies, diversity in HPC, the recent RFI from DOE and what the future might hold, the enormous contributions of UC Berkeley to computing technologies and scientific research and how it stays in the forefront, and proposals for a new college. We also touch on a few of Dr. Yelick’s research projects such as Partitioned Global Address Space (PGAS) and the ExaBiome project and the Berkeley Benchmarking and Optimization (Bebop).
The storied Aurora exascale supercomputer at Argonne National Lab is making progress as blades for the system are reportedly shipping. This was part of the news from the well-crafted and executed Intel Innovation Day. Open source software is a big part of the HPC/AI puzzle and Linux wars are heating up. The Tesla AI day provided some info on what is new with their home-grown AI chip and the associated system.
We caught up with Steve Conway, well-known HPC executive and analyst formerly with IDC and Hyperion Research, in an engaging and wide ranging discussion. We start with Edge HPC and trends towards massively-distributed massively-heterogeneous computing, which takes us to convergence of HPC and AI, mixed precision spectrum, the importance of simulation, the impact of exascale on general computing, global policies, China and Europe, the impact on scientific collaboration, differences in funding models, and the necessary ingredients to attract top talent.
Highlights from the recent Hot Chips conference with discussions of UCIe and why it could cause a ripple effect in the industry, Moore’s law and 3D packaging, Silicon Photonics, inference in the device or in the data center, silicon for the edge, CXL, and code generation. This is followed by an update on Quantum Computing following two important papers on quantum machine learning and unstructured NP-complete problems. The field continues to be in its infancy while making rapid and significant progress. We end with a review of the dedication ceremonies for the Frontier exascale system. Join us.
Following reports that ASML is under diplomatic pressure to regulate the export of its fabrication equipment to China, we discuss market data, other suppliers of fab equipment, and a quick view of some of ASML’s own suppliers. Also covered are the differences between the approach to Exascale in China and the US based on recent research by Hyperion. We end the episode by setting up the vast universe that is the modern HPC software stack as we prepare to cover it systematically over several episodes. We welcome suggestions for guests who can shed light on the state of software in specific layers.
Following the Request for Information (RFI) issued last week by the DOE, we caught up with Dr. Horst Simon, Special Advisor to the Laboratory Director at Lawrence Berkeley National Laboratory (LBNL) and co-editor of the TOP500 list since 2000, to take us through how the DOE is gearing up to go beyond Exascale. A very insightful conversation touching on many aspects of what’s next!
The HPC User Forum held a special event at Oak Ridge National Laboratory last week, complete with an opportunity to get a viewing of the facilities (not quite a tour) and discussions of Exascale Computing and beyond. Doug Black was on the scene and we discuss what all went down. Of special note is the staffing challenges of HPC sites, and the brewing strategy about how future leadership computing systems would look like. This is an important topic that we have covered with our guests in previous episodes and some patterns are emerging as we continue to analyze the future of supercomputing hardware and software.
Recent winner of the Purple Ribbon Medal, one of Japan’s highest honors, Prof. Satoshi Matsuoka, director of the RIKEN Center for Computational Science (R-CCS) and professor of computer science at Tokyo Institute of Technology, joins us in a super fun conversation that covers a wide range of topics (time stamps inside parenthesis).
At RIKEN, Prof. Matsuoka oversaw the development and launch of the Fugaku supercomputer, currently holding the number 1 spot on the TOP500 list. As the list is about to get updated, next week, there is an expectation that the Frontier supercomputer at ORNL (which we covered in a previous episode) will claim the number 1 spot but Fugaku will likely retain its lead in some benchmarks. Previously, he was lead developer of another well-know supercomputer, TSUBAMI, the most powerful supercomputer in Japan at the time.
Here are the topics and the time-stamp in the podcast when they are discussed:
(start) The Purple Ribbon Medal of Honor
(minute 2:15) The role of Japan in supercomputing
(3:45) TOP500 and ORNL’s Exascale system
(5:00) Fugaku and Arm
(8:00) Why not SPARC
(11:30) The balance and beuty of Fugaku and its predecessor the K-Computer
(15:15) Notable applications of Fugaku, including Covid research
(25:00) Future of supercomputing and what’s next after Fugaku
(31:45) FPGA and CGRA
(36:00) Quantum Computing
(40:30) Nintendo days and working with the late great Iwata-san
Jack Dongarra is a leader in supercomputing technologies, parallel programming tools and technologies, and linear algebra and numerical algorithms. He holds appointments at the University of Tennessee, Oak Ridge National Laboratory, and the University of Manchester, and is the recipient of several awards and honors.
In a wide ranging discussion, we cover the Turing Award, TOP500, the state of HPC benchmarks, China’s Exascale systems, and future directions in algorithms. We also talk about future of supercomputing and AI systems, reminisce about a period where a proliferation of system architectures provides a fertile ground for experimentation, and discuss whether we are entering a similar era now. This is another episode you’d want to listen to more than once!
New research paper puts China’s Exascale systems back in the news. And impending acquisition of Twitter leads to a discussion about the positive impact and policy challenges of our tech society.
Join us as we get a rare behind-the-scenes glimpse of how the Frontier supercomputer came to be, how it was built in the middle of a pandemic, and how it is going through its paces. Frontier is a $600 million 30 MW supercomputer, comprised of 50-60 million parts in 100+ cabinets, deployed at the Oak Ridge National Laboratory (ORNL) by HPE using AMD CPUs and GPUs. It is slated to be the United States’ first exascale computing resource with a target performance of about 1.5 exaFLOPS in double-precision (64-bit) arithmetic.
Our special guest, Dr. Jeff Nichols, oversees the Department of Energy’s National Center for Computational Sciences, and as such he has been a key figure in the installation of breakthrough supercomputers such as Titan, Summit, and now Frontier. Dr. Nichols is Associate Laboratory Director for Oak Ridge National Lab’s Computing and Computational Sciences organization. He has been in that position since April 2009. His appearance today is something of a valedictory because he plans to retire this year after 20 years at Oak Ridge. We discuss the past and future of supercomputing as well as the current state of the Frontier supercomputer.
This is part 2 of a special 2-episode discussion of AI in Science with Rick Stevens, Associate Laboratory Director and leader of Exascale Computing Initiative at Argonne National Laboratory and Professor at University of Chicago. In addition to the new ways AI can help advance science, we also discuss ethics, bias, robustness, security,and explainability of AI, and whether AI can replace scientists. We end with a snapshot of Quantum Information Science (QIS), a promising area albeit in its earlier stages of development compared to AI.
A special 2-episode discussion of AI in Science with Rick Stevens, Associate Laboratory Director and leader of Exascale Computing Initiative at Argonne National Laboratory and Professor at University of Chicago. Rick also led a series of Town Halls during 2019 focused on the relevance and applications of AI in scientific research. Held at Argonne, Oak Ridge, and Berkeley National Laboratories, the events were attended by over 1,000 scientists and engineers. This is part 1 of our conversation. Join us.
After SC21, Patrick Kennedy of Serve the Home online publication got quite the scoop, Raja’s Chip Notes Lay Out Intel’s Path to Zettascale, when he met with Raja Koduri, SVP and GM of Intel’s Accelerated Computing Systems and Graphics (AXG) Group, to discuss Zettascale projections and plans, stipulating a 2027 timeframe. Is that realistic when Exascale has not quite been made official? Tune in and let us know what you think.
What Happened at the SC21 Supercomputing Conference? InsideHPC “pulled together a quartet of HPC thought leaders from the technology analyst and national lab communities to gather their reflections”. See the video in this article: Thoughts on SC21: Exascale, TOP500, Diversity in HPC, Quantum, the Metaverse
“What we are seeing is the partitioning of the internet, according to geopolitical winds,” Shahin Khan, partner at consulting firm OrionX.net, told us. “I also think that we are moving from geopolitics to ‘techno-politics,’ and that the significance of technology in determining balances of power around the world is becoming more pronounced. That means we are in a new zone, a new regime, where technological advances have a much more direct impact on geopolitical considerations than they did before. Certainly with AI and 5g, the pandemic, robotics and cryptocurrencies, with quantum computing, we’re seeing that every one of these technology megatrends is becoming a race for national competitiveness. It means that technology is no longer its own thing, it is central to how balance of power on the global scene is going to pan out.”
OrionX is a team of industry analysts, marketing executives, and demand generation experts. With a stellar reputation in Silicon Valley, OrionX is known for its trusted counsel, command of market forces, technical depth, and original content.
From SiliconANGLE theCUBE: Technology analyst Shahin Khan discusses the intersection of HPC with key industry trends such as 5G, IoT, edge, blockchain AI and quantum computing.
On the Monday of the conference, a new leader on the TOP500 list was announced. The Sunway TaihuLight system uses a new processor architecture that is Single-Instruction-Multiple-Data (SIMD) with a pipeline that can do eight 64-bit floating-point calculations per cycle.
This started us thinking about vector processing, a time-honored system architecture that started the supercomputing market. When microprocessors advanced enough to enable massively parallel processing (MPP) systems and then Beowulf and scale-out clusters, the supercomputing industry moved away from vector processing and led the scale-out model.
Later that day, at the “ISC 2016 Vendor Showdown”, NEC had a presentation about its project “Aurora”. This project aims to combine x86 clusters and NEC’s vector processors in the same high bandwidth system. NEC has a long history of advanced vector processors with its SX architecture. Among many achievements, it built the Earth Simulator, a vector-parallel system that was #1 on the TOP500 list from 2002 to 2004. At its debut, it had a substantial (nearly 5x) lead over the previous #1.
Close integration of accelerator technologies with the main CPU is, of course, a very desirable objective. It improves programmability and efficiency. Along those lines, we should also mention the Convey system, which goes all the way, extending the X86 instruction set, and performing the computationally intensive tasks in an integrated FPGA.
A big advantage of vector processing is that it is part of the CPU with full access to the memory hierarchy. In addition, compilers can do a good job of producing optimized code. For many codes, such as in climate modelling, vector processing is quite the right architecture.
Vector parallel systems extended the capability of vector processing and reigned supreme for many years, for very good reasons. But MPPs pushed vector processing back, and GP-GPUs pushed it further still. GPUs leverage the high volumes that the graphics market provides and can provide numerical acceleration with some incremental engineering.
But as usual, when you scale more and more, you scale not just capability, but also complexity! Little inefficiencies start adding up until they become a serious issue. At some point, you need to revisit the system and take steps, perhaps drastic steps. The Sunway TaihuLight system atop the TOP500 list is an example of this concept. And there are new applications like deep learning that look like they could use vectors to quite significant advantage.
Shahin is a technology analyst and an active CxO, board member, and advisor. He serves on the board of directors of Wizmo (SaaS) and Massively Parallel Technologies (code modernization) and is an advisor to CollabWorks (future of work). He is co-host of the @HPCpodcast, Mktg_Podcast, and OrionX Download podcast.
There has been much discussion in recent years as to the continued relevance of the High Performance Linpack (HPL) benchmark as a valid measure of the performance of the world’s most capable machines, with some supercomputing sites opting out of the TOP500 completely such as National Center for Supercomputing Applications at the University of Illinois at Urbana-Champaign that houses the Cray Blue Waters machine. Blue Waters is claimed to be the fastest supercomputer on a university campus, although without an agreed benchmark it is a little hard to verify such a claim easily.
At a superficial level it appears as though any progress in the upper echelons of the TOP500 may have stalled with little significant change in the TOP10 in recent years and just two new machines added to that elite group in the November 2015 list: Trinity at 8.10 Pflop/s and Hazel Hen at 5.64 Pflop/s, both Cray systems increasing the company’s share of the TOP10 machines to 50%. The TOP500 results are available at http://www.top500.org.
A new benchmark – the High Performance Conjugate Gradients (HPCG) – introduced two years ago was designed to be better aligned with modern supercomputing workloads and includes system features such as high performance interconnects, memory systems, and fine grain cooperative threading. The combined pair of results provided by HPCG and HPL can act as bookends on the performance spectrum of any given system. As of July 2015 HPCG had been used to rank about 40 of the top systems on the TOP500 list.
The November TOP500 List: Important Data for Big Iron
Although being complemented by other benchmarks, the HPL-based TOP500 is still the most significant resource for tracking the pace of super computing technology development historically and for the foreseeable future.
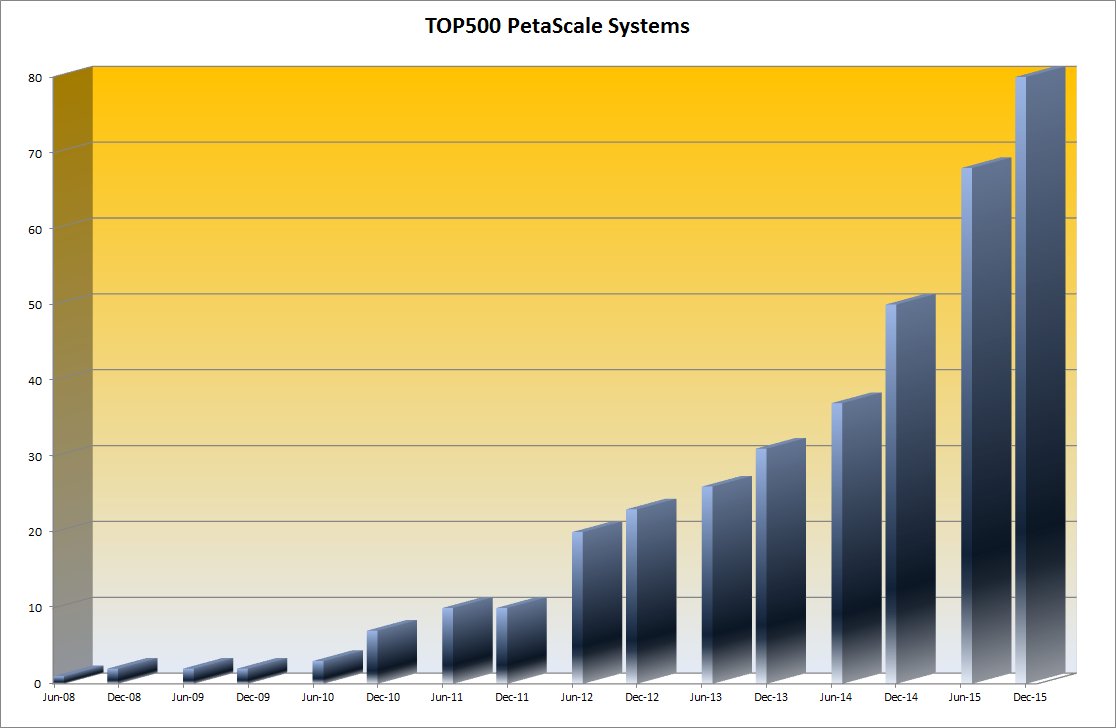
The first petascale machine, ‘Roadrunner’, debuted in June 2008, twelve years after the first terascale machine – ASCI Red in 1996. Until just a few years ago 2018 was the target for hitting the exascale capability level. As 2015 comes to its close the first exascale machine seems much more likely to debut in the first half of the next decade and probably later in that window rather than earlier. So where are we with the TOP500 this November, and what can we expect in the next few lists?
Source: TOP500
Highlights from the November 2015 TOP500 List on performance:
– The total combined performance of all 500 systems had grown to 420 Pflop/s, compared to 361 Pflop/s last July and 309 Pflop/s a year previously, continuing a noticeable slowdown in growth compared to the previous long-term trend.
– Just over 20% of the systems (a total of 104) use accelerator/co-processor technology, up from 90 in July 2015
– The latest list shows 80 petascale systems worldwide making a total of 16% of the TOP500, up from 50 a year earlier, and significantly more than double the number two years earlier. If this trend continues the entire TOP100 systems are likely to be petascale machines by the end of 2016.
So what do we conclude from this? Certainly that the road to exascale is significantly harder than we may have thought, not just from a technology perspective, but even more importantly from a geo-political and commercial perspective. The aggregate performance level of all of the TOP500 machines has just edged slightly over 40% of the HPL metric for an exascale machine.
Most importantly, increasing the number of petascale-capable resources available to scientists, researchers, and other users up to 20% of the entire list will be a significant milestone. From a useful outcome and transformational perspective it is much more important to support advances in science, research and analysis than to ring the bell with the world’s first exascale system on the TOP500 in 2018, 2023 or 2025.
Architecture
As acknowledged by the introduction of HPCG, HPL and the TOP500 performance benchmark are only one part of the HPC performance equation.
The combination of modern multi-core 64 bit CPUs and math accelerators from Nvidia, Intel and others have addressed many of the issues related to computational performance. The focus on bottlenecks has shifted away from computational strength to data-centric and energy issues, which from a performance perspective influence HPL results but are not explicitly measured in the results. However, from an architectural perspective the TOP500 lists still provide insight into the trends in an extremely useful manner.
Source: TOP500
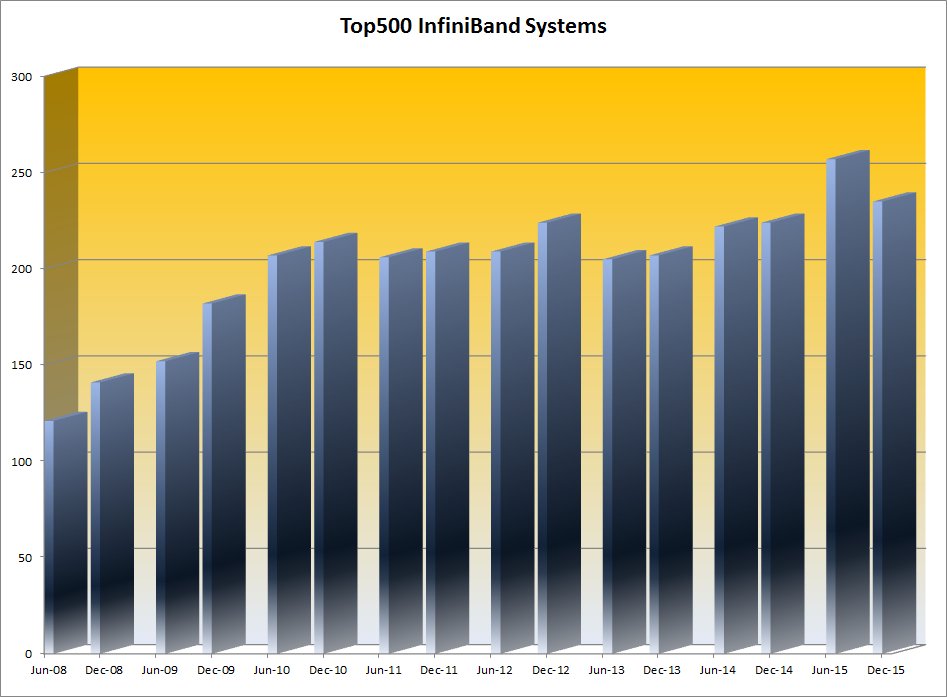
Observations from the June 2015 TOP500 List on system interconnects:
– After two years of strong growth from 2008 to 2010, InfiniBand-based TOP500 systems plateaued at 40% of the TOP500 while compute performance grew aggressively with the focus on hybrid, accelerated systems.
– The uptick in InfiniBand deployments June 2015 to over 50% of the TOP500 list for the first time does not appear to be the start of a trend, with Gigabit Ethernet systems increasing to over a third (36.4%) of the TOP500, up from 29.4%.
The TOP500: The November List and What’s Coming Soon
Although the TOP10 on the list have shown little change for a few years, especially with the planned upgrade to Tianhe 2 blocked by the US government, there are systems under development in China that are expected to challenge the 100 Pflop/s barrier in the next twelve months. From the USA, Coral initiative is expected to significantly exceed the 100 Pflop/s limit – targeting the 100 to 300 Pflop/s with two machines from IBM and one from Cray, but not before the 2017 time frame. None of these systems are expected to deliver more than one third of exascale capability.
Vendors: A Changing of the Guard
The USA is still the largest consumer of TOP500 systems with 40% of the share by system count, which clearly favors US vendors, but there are definite signs of change on the wind.
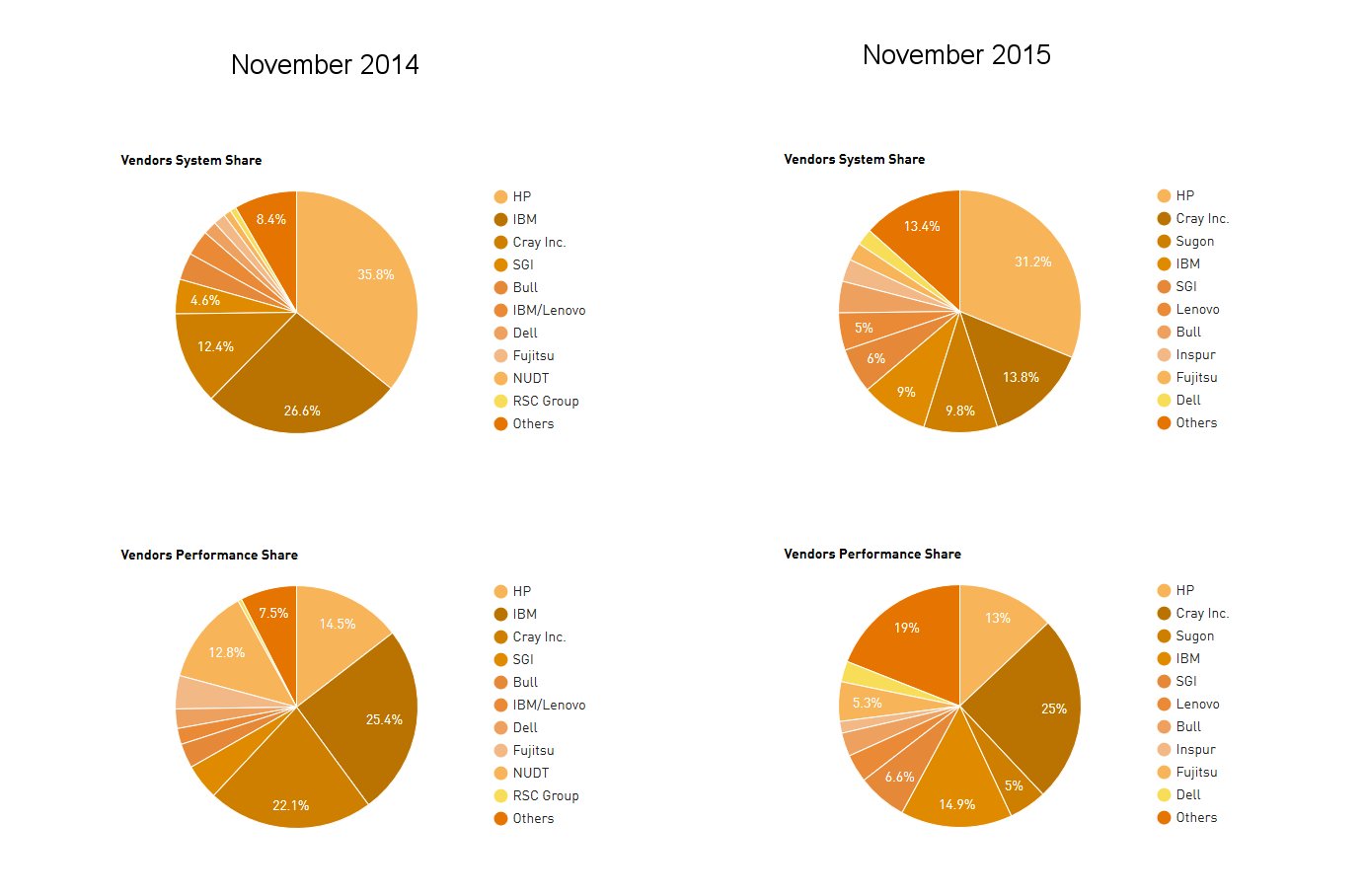
Cray is the clear leader in performance with a 24.9 percent share of installed total performance, roughly the same as a year earlier. Each of the other leading US vendors is experiencing declining share with IBM in second place with a 14.9 percent share, down from 26.1 percent last November. Hewlett Packard is third with 12.9 percent, down from 14.5 percent twelve months ago.
These trends are echoed in the system count numbers. HP has the lead in systems and now has 156 (31%), down from 179 systems (36%) twelve months ago. Cray is in second place with 69 systems (13.8%), up from 12.4% last November. IBM now has 45 systems (9%), down from 136 systems (27.2%) a year ago.
On the processor architecture front a total of 445 systems (89%) are now using Intel processors, slightly up from 86.2 percent six months ago, with IBM Power processors now at 26 systems (5.2%), down from 38 systems (7.6%) six month ago.
Source: TOP500
Geo-Political Considerations
Perhaps the single most interesting insight to come out of the TOP500 has little to do with the benchmark itself, and the geographical distribution data which in itself underscores the importance of the TOP500 lists in tracking trends.
The number of systems in the United States has fallen to the lowest point since the TOP500 list was created in 1993, down to 201 from 231 in July. The European share has fallen to 107 systems compared to 141 on the last list and is now lower than the Asian share, which has risen to 173 systems, up from 107 the previous list and with China nearly tripling the number of systems to 109. In Europe, Germany is the clear leader with 32 systems, followed by France and the UK at 18 systems each. Although the numbers for performance-based distributions vary slightly, the percentage distribution is remarkably similar.
The USA and China divide over 60% of the TOP500 systems between them, with China having half the number and capability of the US-based machines. While there is some discussion about how efficiently the Chinese systems are utilized in comparison to the larger US-based systems, that situation is likely to be temporary and could be addressed by a change in funding models. It is abundantly clear that China is much more serious about increasing funding for HPC systems while US funding levels continue to demonstrate a lack of commitment to maintaining development beyond specific areas such as high energy physics.
TOP500: “I Have Seen The Future and it Isn’t Exascale”
The nature of HPC architectures, workloads and markets are all in flux in the next few years, and an established metric such as the TOP500 is an invaluable tool to monitor the trends. Even though HPL is no longer the only relevant benchmark, the emergence of complementary benchmarks such as HPCG serves to enhance the value of the TOP500, not to diminish it. It will take a while to generate a body of data equivalent to the extensive resource that has been established by the TOP500.
What we can see from the current trends shown in the November 2015 TOP500 list is that although an exascale machine will be built eventually, it almost certainly will not be delivered this decade and possibly not until half way through the next decade. Looking at the current trends it is also very unlikely that the first exascale machine will be built in the USA, and much more likely that it will be built in China.
Over the next few years the TOP500 is likely to remain the best tool we have to monitor geo-political and technology trends in the HPC community. If the adage coined by the Council on Competitiveness, “To out-compute is to out-compete” has any relevance, the TOP500 will likely provide us with a good idea of when the balance of total compute capability will shift from the USA to China.
Last week, in Part 1 of this two-part blog, we looked at trends in Big Data and analytics, and started to touch on the relationship with HPC (High Performance Computing). In this week’s blog we take a look at the usage of Big Data in HPC and what commercial and HPC Big Data environments have in common, as well as their differences.
High Performance Computing has been the breeding ground for many important mainstream computing and IT developments, including:
The Web
Cluster computing
Cloud computing
Hi-quality visualization and animation
Parallel computing
and arguably, Big Data itself
Big Data has indeed been a reality in many HPC disciplines for decades, including:
Particle physics
Genomics
Astronomy
Weather and climate modeling
Petroleum seismic processing
Horseshoe Falls (portion of Niagara Falls on Canadian side)
All of these fields and others generate massive amounts of data, which must be cleaned, calibrated, reduced and analyzed in great depth in order to extract knowledge. This might be a new genetic sequence, the identification of a new particle such as the Higgs Boson, the location and characteristics of an oil reservoir, or a more accurate weather forecast. And naturally the data volumes and velocity are growing continually as scientific and engineering instrumentation becomes more advanced.
A recent article, published in the July 2015 issue of the Communications of the ACM, is titled “Exascale computing and Big Data”. Authors Daniel A. Reed and Jack Dongarra note that “scientific discovery and engineering innovation requires unifying traditionally separated high-performance computing and big data analytics”.
(n.b. Exascale is 1000 x Petascale, which in turn is 1000 x Terascale. HPC and Big Data are already well into the Petascale era. Europe, Japan, China and the U.S. have all announced Exascale HPC initiatives spanning the next several years.)
What’s in common between Big Data environments and HPC environments? Both are characterized by racks and racks of commodity x86 systems configured as compute clusters. Both environments have compute system management challenges in terms of power, cooling, reliability and administration, scaling to as many as hundreds of thousands of cores and many Petabytes of data. Both are characterized by large amounts of local node storage, increasing use of flash memory for fast data access and high-bandwidth switches between compute nodes. And both are characterized by use of Linux OS operating systems or flavors of Unix. Open source software is generally favored up through the middleware level.
What’s different? Big Data and analytics uses VMs above the OS, SANs as well as local storage, the Hadoop (parallel) file system, key-value store methods, and a different middleware environment including Map-Reduce, Hive and the like. Higher-level languages (R, Python, Pig Latin) are preferred for development purposes.
HPC uses C, C++, and Fortran traditional compiler development environments, numerical and parallel libraries, batch schedulers and the Lustre parallel file system. And in some cases HPC systems employ accelerator chips such as Nvidia GPUs or Intel Xeon Phi processors, to enhance floating point performance. (Prediction: we’ll start seeing more and more of these used in Big Data analytics as well – http://www.nvidia.com/object/data-science-analytics-database.html).
But in both cases the pipeline is essentially:
Data acquisition -> Data processing -> Model / Simulation -> Analytics -> Results
The analytics must be based on and informed by a model that is attempting to capture the essence of the phenomena being measured and analyzed. There is always a model — it may be simple or complex; it may be implicit or explicit.
Human behavior is highly complex, and every user, every customer, every patient, is unique. As applications become more complex in search of higher accuracy and greater insight, and as compute clusters and data management capabilities become more powerful, the models or assumptions behind the analytics will in turn become more complex and more capable. This will result in more predictive and prescriptive power.
Our general conclusion is that while there are some distinct differences between Big Data and HPC, there are significant commonalities. Big Data is more the province of social sciences and HPC more the province of physical sciences and engineering, but they overlap, and especially so when it comes to the life sciences. Is bioinformatics HPC or Big Data? Yes, both. How about the analysis of clinical trials for new pharmaceuticals? Arguably, both again.
So cross-fertilization and areas of convergence will continue, while each of Big Data and HPC continue to develop new methods appropriate to their specific disciplines. And many of these new methods will crossover to the other area when appropriate.
The National Science Foundation believes in the convergence of Big Data and HPC and is putting $2.4 million of their money into this at the University of Michigan, in support of various applications including climate science, cardiovascular disease and dark matter and dark energy. See:
Stephen Perrenod has lived and worked in Asia, the US, and Europe and possesses business experience across all major geographies in the Asia-Pacific region. He specializes in corporate strategy for market expansion, and cryptocurrency/blockchain on a deep foundation of high performance computing (HPC), cloud computing and big data. He is a prolific blogger and author of a book on cosmology.
Data volumes, velocity, and variety are increasing as consumer devices become more powerful. PCs, smart phones and tablets are the instrumentation, along with the business applications that continually capture user input, usage patterns and transactions. As devices become more powerful each year (each few months!) the generated volumes of data and the speed of data flow both increase concomitantly. And the variety of available applications and usage models for consumer devices is rapidly increasing as well.
Are the Big Data and HPC disciplines converging or diverging?
Holding more and more data in-memory, via in-memory databases and in-memory computing, is becoming increasingly important in Big Data and data management more broadly. HPC has always required very large memories due to both large data volumes and the complexity of the simulation models.
Igauzu Falls: By Mario Roberto Duran Ortiz Mariordo (Own work) CC BY 3.0, via Wikimedia Commons
Volume and Velocity and Variety
As is often pointed out in the Big Data field, it is the analytics that matters. Collecting, classifying and sorting data is a necessary prerequisite. But until a proper analysis is done, one has only expended time, energy and money. Analytics is where the value extraction happens, and that must justify the collection effort.
Applications for Big Data include customer retention, fraud detection, cross-selling, direct marketing, portfolio management, risk management, underwriting, decision support, and algorithmic trading. Industries deploying Big Data applications include telecommunications, retail, finance, insurance, health care, and the pharmaceutical industry.
There are a wide variety of statistical methods and techniques employed in the analytical phase. These can include higher-level AI or machine learning techniques e.g. neural networks, support vector machines, radial basis functions, and nearest neighbor methods. These imply a significant requirement for a large number of floating point operations, which is characteristic of most of HPC.
For one view on this, here is a recent report on InsideHPC.com and video on “Why HPC is so important to AI”
If one has the right back-end applications and systems then it is possible to keep up with the growth in data and perform the deep analytics necessary to extract new insights about customers, their wants and desires, and their behavior and buying patterns. These back-end systems increasingly need to be of the scale of HPC systems in order to stay on top of all of the ever more rapidly incoming data, and to meet the requirement to extract maximum value.
In Part 2 of this blog series, we’ll look at how Big Data and HPC environments differ, and at what they have in common.
Stephen Perrenod has lived and worked in Asia, the US, and Europe and possesses business experience across all major geographies in the Asia-Pacific region. He specializes in corporate strategy for market expansion, and cryptocurrency/blockchain on a deep foundation of high performance computing (HPC), cloud computing and big data. He is a prolific blogger and author of a book on cosmology.